By OrientDB Developer Gabriele Ponzi
Big Data is an important topic nowadays. The large amount of data and their unstructured and heterogeneous nature have exposed the limitations of the relational database model.
In order to restrict these barriers in recent years, the NoSQL movement was born, which proposed new procedural and architectural approaches. Among these technologies are graph databases, innovative databases which organize and manage information in a graph structure, applied in the representation of complex networks such as social ones.
For these reasons, more and more people are intrigued by products like OrientDB.
Teleporter’s Answer to the Migration Problem
Despite the wide variety of new solutions, we are often reluctant to switch to new technologies for several reasons. First of all, migration from the old DB to the new one. Migration requires substantial costs and takes considerable time, because the task is usually commissioned to specialized companies who perform it manually and individually for the customer.
This reality prompted the OrientDB team to develop Teleporter. Teleporter is a free tool which allows an automated and quick migration from a relational database to the OrientDB graph database.
Teleporter was conceived to satisfy various requirements:
- Ensure high versatility, in order to make the import ductile and effective for different use cases.
- Provide a low configuration level, in order to be quickly usable, and offer a certain degree of customization to the process by making available different strategies and approaches that allow to overcome the automatic nature of the tool.
- Ensure high scalability.
Problem: How can we achieve an automatic migration between two DBMSs that manage data in different ways? The answer is by defining an effective and efficient mapping between the two models in question: the relational and the graph model.
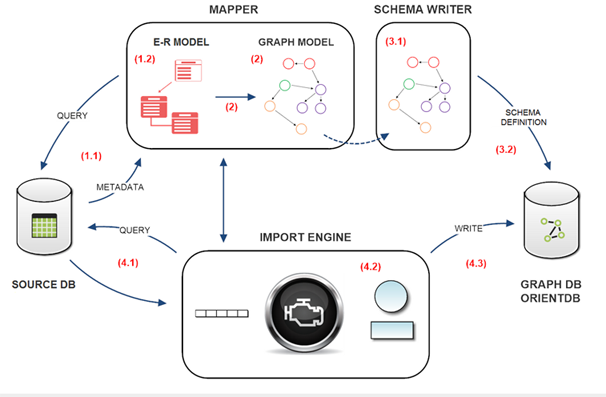
The whole process consists of 4 phases:
1. Source DB Schema Building (E-R model): the source DB schema is built by querying the source DB metadata.
2. Graph Model Building: a correspondent and coherent Graph Model is built.
3. OrientDB Schema Writing: the OrientDB schema is written according to the Graph Model just built.
4. OrientDB importing: importing data from the source DB to the graph database of OrientDB.
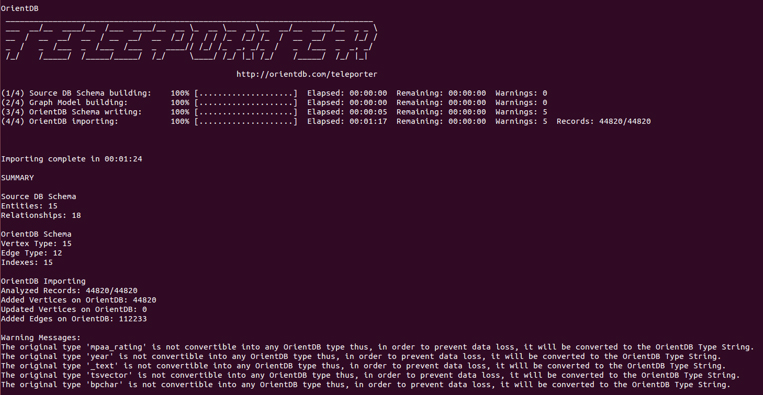
Below is an OrientDB Teleporter execution dump:
Execution Strategies
The Graph Model’s expressive power allows it to perform various optimizations based on the aggregation of data. For this reason, Teleporter provides two different import strategies:
- naive strategy
- naive-aggregate strategy
The naive strategy follows a direct transformation approach between the E-R model of the source DB and the correspondent Graph Model, in which:
- Each Entity (or Table) with its attributes is converted in a “Vertex-Type” (an OrientDB vertex class).
- Each Relationship between two entities is converted in a “Edge-Type” (an OrientDB edge class).
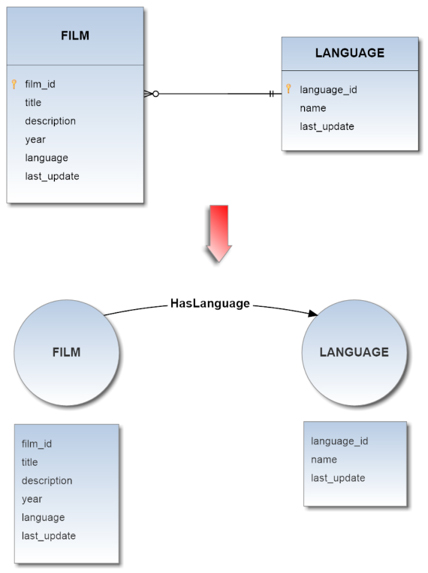
This strategy is fast and requires less transformation rules. Nevertheless, a certain degree of redundancy is permitted.
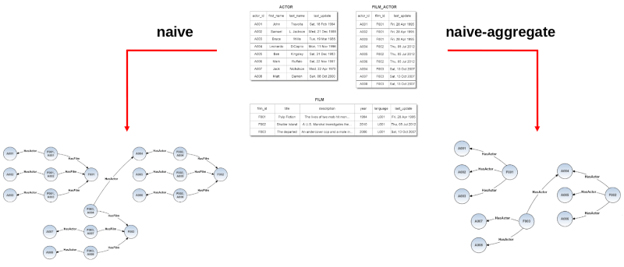
As you can see in the following example, in the relational model the only function of the film_actor join table is to represent a many-to-many relationship between movies and actors, which in OrientDB has been converted into a Vertex-Type.
Thus the second strategy aggregates complex relationships into “aggregator-edges”, simplifying the structure of the resulting graph model.
In this way, even if this strategy requires more transformation rules, we obtain an overhead reduction and better performance on the graph imported in OrientDB.
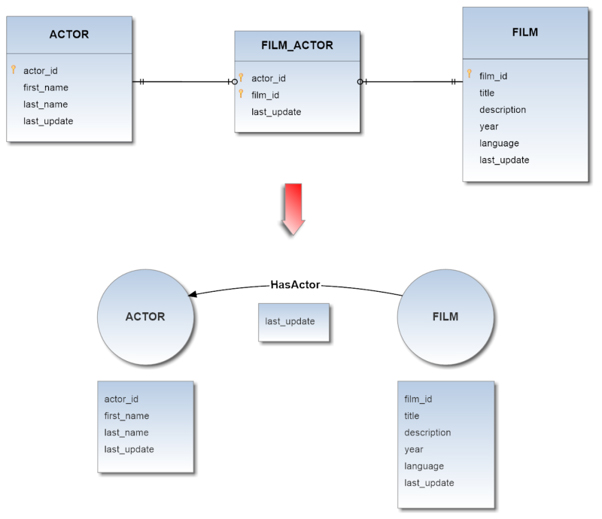
The following example show how two different strategies can be used on the same source DB to aggregate data. On the left a naive translation of tables and on the right, an optimized naive-aggregate solution.
Sequential executions and one-way Synchronizer
Teleporter is conceived to support many sequential executions from the same source DB to the same graph DB of OrientDB, in this way you can:
- Personalize your import, combining the different strategies and settings by including or excluding the chosen tables and by running Teleport more times in order to obtain a more complex and customized import strategy.
- Use it as a one-way synchronizer and maintain a copy of your DB: all the changes applied to the source DB (primary DB) are propagated to the imported graph DB, but not vice versa.
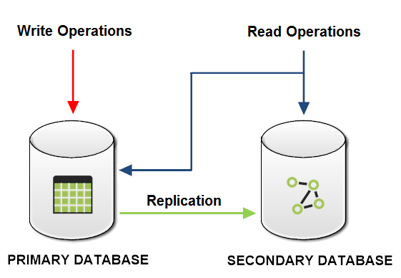
Thus if you want that your data remain synchronized you have to perform the write operations only on the primary database, but you can perform the reads on both databases.
Other features
Teleporter currently offers other features adoptable during the import process:
- Inheritance relationships inference
- Filters based on white-list and black-list policies
- Autorename of all elements in the source DB according to the Java convention
- Driver JDBC auto-configuration
- Output Manager with 5 different verbosity levels
These will be shown and discussed in the next posts.
Usage Example
Teleporter is a tool written in Java, but it can be used as a tool thanks to the teleporter.sh script (or .bat on Windows).
oteleporter.sh -jdriver <jdbc-driver> -jurl <jdbc-url> -ourl <orientdb-url>
[-juser <username>] [-jpasswd <password>] [-s <strategy>]
[-nr <name-resolver>] [-v <verbose-level>]
([-include <table-names>] | [-exclude <table-names>]
[-inheritance <orm-technology>:<ORM-file-url>]
The main arguments necessary for migration are:
- -jdriver is the driver name of the DBMS from which you want to execute the import.
- -jurl is the JDBC URL giving the location of the source DB to import.
- -juser is the username to access the source DB.
- -jpasswd is the password to access the source DB.
- -ourl is the URL for the destination Orient graph DB.
Through the argument “-s” we can choose the strategy adopted during the importing phase. If not specified, naive-aggregate strategy is adopted. Possible values:
- Naive: performs a "naive" import of the data source. The data source schema is translated semi-directly in a correspondent and coherent graph model.
- Naive-aggregate: performs a "naive" import of the data source. The data source schema is translated semi-directly in a correspondent and coherent graph model using an aggregation policy on the join tables.
In the following example, we’ll import the source DB “testdb” from a PostgreSQL DBMS to OrientDB through the naive strategy:
oteleporter.sh -jdriver postgresql -jurl jdbc:postgresql://localhost:5432/testdb
-juser username -jpasswd password
-ourl plocal:$ORIENTDB_HOME/databases/testdb
-s naive
Compatibilities
Teleporter is compatible with all the RDBMS that have a JDBC driver. We have successfully tested Teleporter with:
- Oracle (last tested version: 12c)
- SQLServer (last tested version: SQLServer 2014)
- MySQL (last tested version: 5.1.35)
- PostgreSQL (last tested version: 9.4-1201)
- HyperSQL (last tested version: 2.3.2)
Teleporter manages all the necessary type conversions for these DBMSs during the import process.
Stay tuned,
Gabriele Ponzi
OrientDB Ltd
References:
Teleporter full documentation: https://github.com/orientechnologies/orientdb-labs/blob/master/Teleporter-Index.md



